Lately, I've been diving deep into the world of parsers and tokenizers, attempting to rebuild Stata from scratch in JavaScript using Chevrotain. It's been an exciting yet incredibly frustrating journey, and I've hit a roadblock that has me questioning my life choices.
The Problem: Context-Sensitive Keywords
In Stata, it's perfectly acceptable for command names to double as variable names. Consider this simple example:
generate generate = 2// example in js
var var = 2; // not validIn my initial implementation, I ran into two major issues:
- My token definitions were matching command keywords like generate indiscriminately, regardless of context.
- The command tokens were checked before identifier tokens in my lexer's order of precedence.
I'm not Alone
After some digging through parsing forums and documentation, I discovered that this isn't an isolated problem. Many language implementers have wrestled with context-sensitive keywords. The common solutions often involve elaborate workarounds ranging from context-tracking mechanisms to entirely separate parsing passes.
Some Suggested Solutions
Token Precedence
Unfortunately, with my current Chevrotain setup, reordering token precedence isn't feasible because Chevrotain is a parser generator library for JS that uses LL(k) parsing techniques.
LL(k) parsing techniques

- top-down parser - starts with the start symbol on the stack, and repeatedly replaces nonterminals until the string is generated.
- predictive parser - predict next rewrite rule
- first L of LL means - read input string left to right
- second L of LL means - produces leftmost derivation
- k - number of lookahead symbols
It provides tools for building a recursive-descent parser with full control over grammar definitions. This doesn't mean it can't handle token precedence—it definitely can—but it requires manual implementation, which involves considerable effort.
Contextual Parsing
Chevrotain has built in support for contextual tokens. We could define our keywords as contextual and enable them only in certain parsing rules.
Post-Lexer Transformation
This is one is an interesting one—post-lexing examines the token stream and reclassifies command tokens to identifiers based on their syntactic position.
Each of these methods has its merits and its tradeoffs. If anyone has tackled this issue from a different angle or has additional suggestions, I'd love to hear your thoughts.
UPDATE:
After careful consideration, I went with the post-lexing token transformation approach. This solution proved to be the most practical for several reasons:
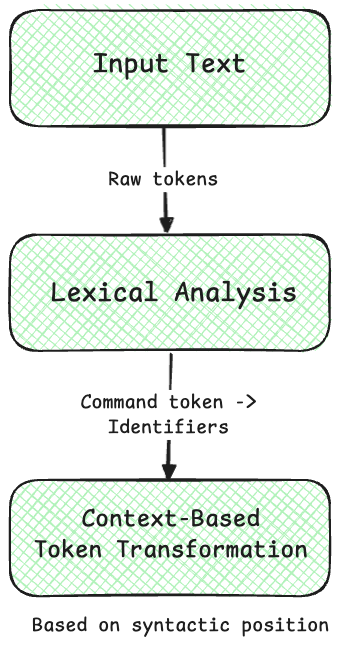
-
Low overhead - it doesn't require modifying the core lexer or parser implementation
-
Easy to maintain - Solution is isolated in a single processing step before lexing and parsing
-
Minimal complexity - No need for complex state machines or multiple parsing passes
-
Predictable behavior - Context-based token reclassification follows clear, documented rules
The key insight was that context sensitivity could be handled by examining token patterns after initial lexing. This approach effectively solves the "generate generate = 1" problem with remarkably little code.