When optimizing our DTA (Stata file format) parser and writer, we discovered several key techniques that dramatically improved performance:
1. Avoiding DataView for High-Performance Binary Operations
original approach:
function writeValue(view: DataView, offset: number, value: number) {
view.setFloat64(offset, value, true);
return offset + 8;
}optimized approach using Uint8Array:
const sharedBuffer = new ArrayBuffer(8);
const sharedUint8 = new Uint8Array(sharedBuffer);
function writeValue(buffer: Uint8Array, offset: number, value: number) {
sharedView.setFloat64(0, value, true); buffer.set(sharedUint8, offset);
return offset + 8;
}DataView operations are significantly slower due to bounds checking and endianness handling.
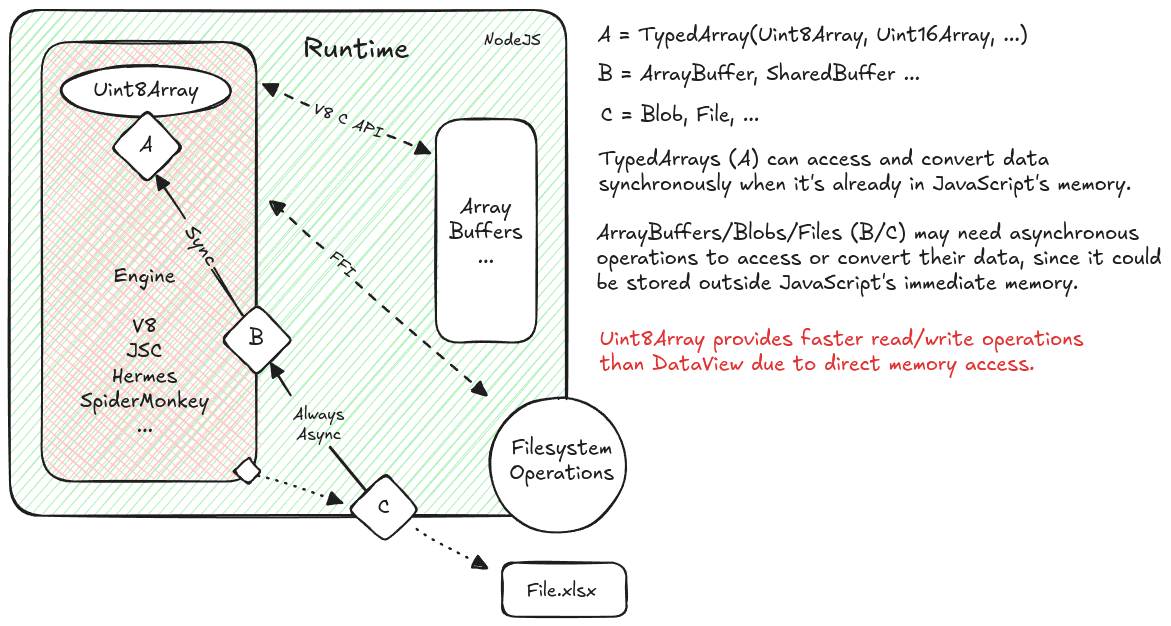
Uint8Array provides faster read/write operations than DataView due to direct memory access.
Here's a diagram that illustrates it.
2. Pre-computing Common Patterns
Rather than computing missing value patterns on demand, we pre-compute them once:
const MISSING_PATTERNS = {
BYTE: new Uint8Array([MISSING_VALUES.BYTE_MISSING]),
FLOAT_NAN: (() => {
const buf = new ArrayBuffer(4);
new DataView(buf).setUint32(0, 0x7fc00000, true);
return new Uint8Array(buf);
})(),
DOUBLE_NAN: (() => {
const buf = new ArrayBuffer(8);
const view = new DataView(buf);
view.setUint32(0, 0, true);
view.setUint32(4, 0x7ff80000, true);
return new Uint8Array(buf);
})(),
};This optimization:
- Eliminates repeated buffer allocations and bit manipulations in hot paths
- Provides immediate access to commonly used patterns
- Reduces cognitive load by centralizing binary pattern definitions
3. Loop Optimization for V8's JIT Compiler
Understanding V8's optimization patterns led us to prefer simple for-loops over higher-order array methods:
// Before: Creates closure and temporary arrays
const formats = Array(nvar)
.fill(null)
.map(() => ({
type: ColumnType.DOUBLE,
maxDecimals: 0,
}));
// After: Simple, predictable loop that V8 can optimize
const formats = new Array(nvar);
for (let i = 0; i < nvar; i++) {
formats[i] = {
type: ColumnType.DOUBLE,
maxDecimals: 0,
};
}
V8's JIT compiler can better optimize simple counting loops because:
- The iteration pattern is predictable
- No closure creation or function call overhead
- Memory allocation pattern is more straightforward
- Better instruction caching due to linear code execution
4. Shared Buffer Strategy for Maximum Efficiency
One of our most impactful optimizations was implementing a shared buffer strategy. Instead of allocating new buffers for each operation, we maintain a single pre-allocated buffer for temporary operations:
// Pre-allocate shared buffers at module level
const SHARED_BUFFER_SIZE = 1024 * 1024; // 1MB shared buffer
const sharedBuffer = new ArrayBuffer(SHARED_BUFFER_SIZE);
const sharedView = new DataView(sharedBuffer);
const sharedUint8 = new Uint8Array(sharedBuffer);
// Different views for different numeric types
const tempBuffers = {
float32: new Float32Array(sharedBuffer),
float64: new Float64Array(sharedBuffer),
uint8: new Uint8Array(sharedBuffer),
dataView: new DataView(sharedBuffer),
};This approach provides several key advantages:
- Eliminates thousands of small buffer allocations that would trigger garbage collection
- Improves CPU cache utilization by reusing the same memory locations
- Reduce memory fragmentation in long-running processes
- Provides specialized view for different numeric types without additional allocations
Key Improvements 📈
Large Files (Best Results)
- ~43% faster conversion time (from 3939ms to 2231ms)
- 34% reduction in peak heap usage (13189MB to 8682MB)
- 52% increase in rows/second processing (5935 to 9030 rows/sec)
Medium Files
- ~41% faster conversion time (260ms to 154ms)
- 33% reduction in peak memory usage (1000MB to 673MB)
- 46% boost in rows/second processing (7139 to 10453 rows/sec)
Small Files
- ~44% faster conversion time (16.47ms to 9.14ms)
- 28% reduction in peak heap usage (85MB to 60MB)
- 42% increase in rows/second processing (8351 to 11930 rows/sec)
Conclusion
The key learning was that understanding V8's optimization strategies and leveraging typed arrays with shared buffers can dramatically improve performance when processing binary data. While some optimizations made the code slightly more complex, the performance benefits justified the trade-offs for our high-throughput use case.
*Remember:*Reserve optimizations for data-heavy critical paths - everywhere else, favor clean, maintainable code.
Thank You, Contributors!
These optimizations were a team effort. Big shoutout to the awesome folks who helped level up our code: